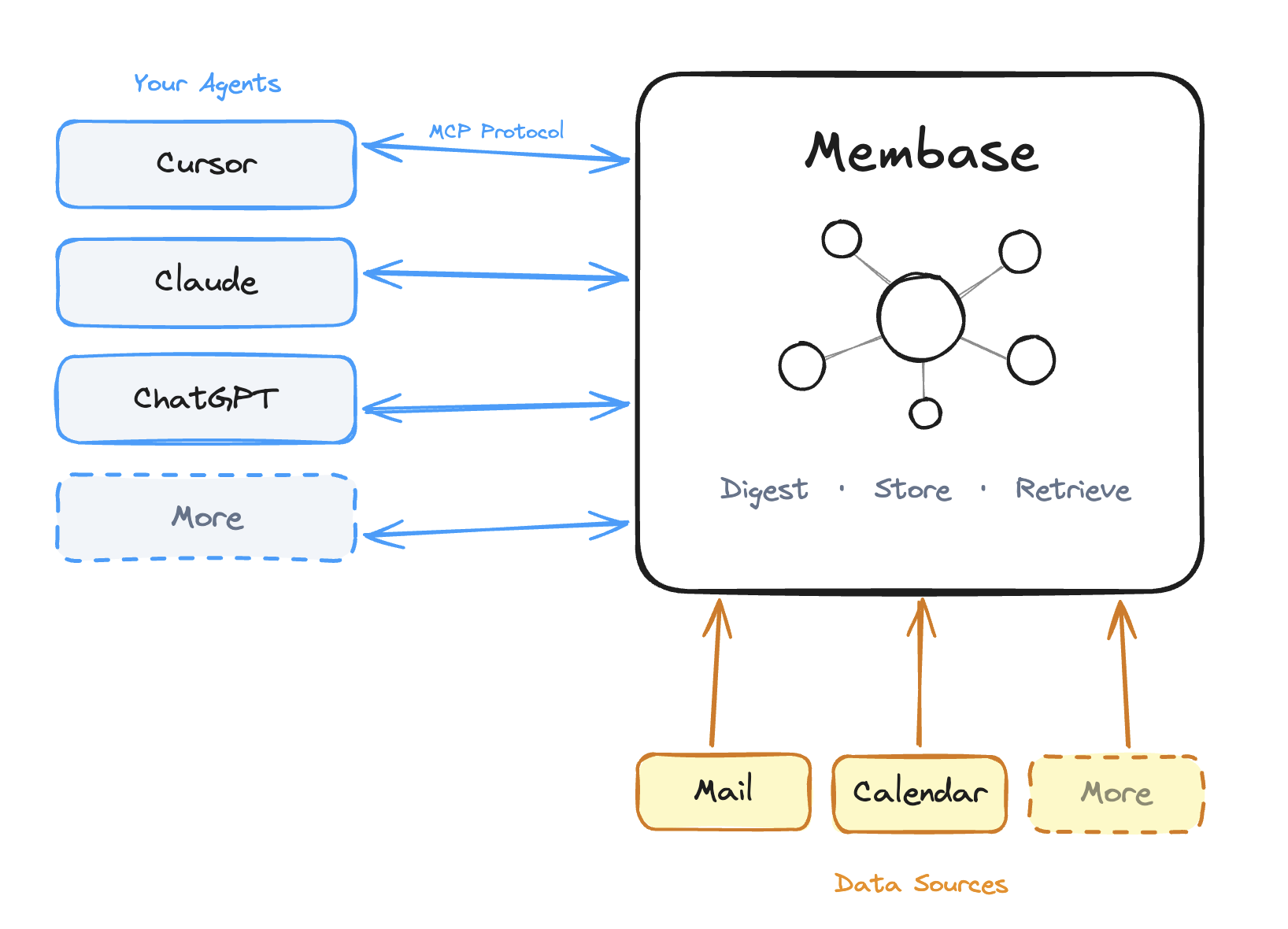
How context flows into Membase’s two knowledge stores (Memory and Wiki), gets structured, and comes back to your agents.
Membase transforms raw context into structured, retrievable knowledge that your agents can pull from across sessions. This page walks through the full lifecycle.
Membase keeps two complementary knowledge stores, each optimized for a different shape of information. Agents can read and write both through MCP, and Chat in Dashboard can consult both when stored context helps.
Membase architecture overview
Memory
Wiki
What it stores
Personal context: preferences, decisions, habits, meetings, emails
Markdown documents linked with [[wikilinks]], organized into Projects or Basic
Primary input
Agent conversations (add_memory), Chat in Dashboard, chat history import, app integrations (Gmail, Calendar, Slack)
You writing documents in the dashboard, Chat in Dashboard, add_wiki calls from agents, Notion live sync, Notion/Obsidian/Markdown imports, supported agent transcript capture
Primary retrieval
search_memory (semantic), Chat in Dashboard, graph and table views
search_wiki (hybrid: keyword + semantic), Chat in Dashboard, graph and table views
Context from either store flows through three stages: ingest → process → retrieve. The rest of this page walks through each stage for both stores.
Memory receives context from imports, agents, Chat in Dashboard, and integrations.
1
Chat History Import (bootstrap)
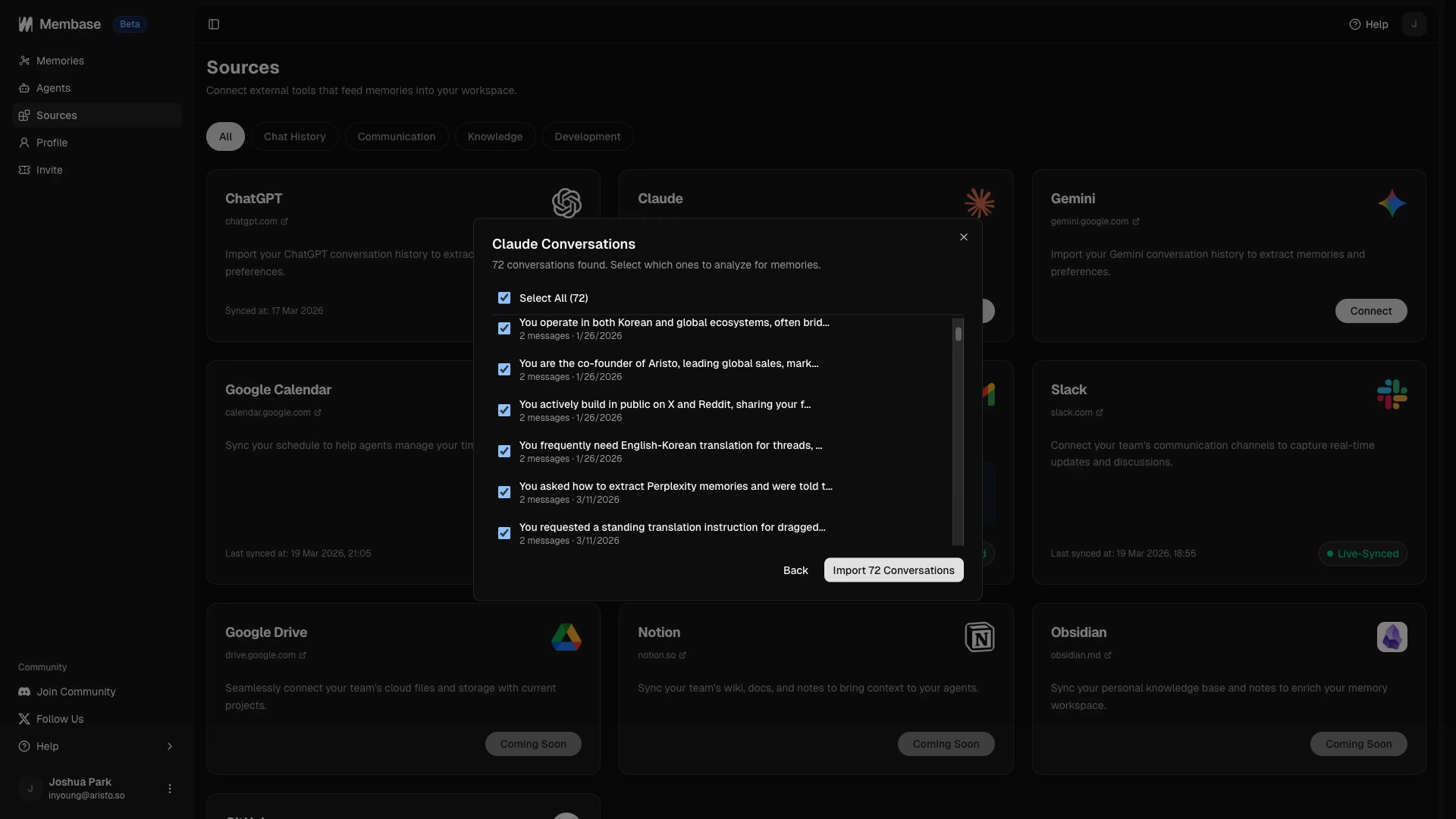
Already have months of conversations in ChatGPT, Claude, or Gemini? Export your chat history and upload it in Sources under the Chat History section. The entire archive goes through the same digesting pipeline as live conversations.
Import your existing conversations from ChatGPT, Claude, and Gemini
2
Live agent conversation
You talk to your agent normally. During the conversation the agent picks up on preferences, decisions, project details, and other durable context, and calls add_memory via MCP.
Example
You: "Let's use Zustand instead of Redux for this project. Also, I prefer functional components over class components."→ Agent calls add_memory with this context
3
Chat in Dashboard
While talking directly to your knowledge base in the dashboard, Chat can save durable personal context as memory when you share something worth keeping.
4
App integration sync
Connected sources (Gmail, Google Calendar, Slack) sync new data automatically in the background. Each message, event, or email becomes an episode.
5
Membase receives the context
Membase accepts the incoming context for processing so the agent or sync can keep moving.
Wiki receives documents directly from you, Chat in Dashboard, or agent tool calls.
1
Wiki import (bootstrap)
Already have a markdown knowledge base? Use Wiki > Add > Import files to import Notion exports, Obsidian vaults, or Markdown files into a target Project or Basic. [[wikilinks]] are preserved where available, and documents upload through the background import flow. See Importing Documents.
2
Write a document in the dashboard
Open the Wiki tab, click Add > Write document, choose a Project or Basic, and write in markdown. Manual save and unsaved-changes warnings keep your content safe.
3
Notion live sync
Connect Notion from Sources, choose the Notion pages available to Membase, then choose a target Wiki Project. Synced pages become source-backed Wiki documents. See App Integrations.
4
Agent calls add_wiki
Your connected agent can call add_wiki when you share factual, reference-style knowledge worth keeping. Example: “Write up our deployment rollback checklist” results in a new wiki document instead of a memory.
5
Supported plugin captures transcript
Supported agent plugins can preserve user/assistant conversation transcripts as original source material in Wiki, separate from extracted personal Memory.
6
Chat creates a document
Chat in Dashboard can also create wiki documents when you ask it to save factual, reference-style material.
7
Membase receives the document
The Wiki document is saved directly or prepared for background processing, depending on whether it came from a direct write, sync, or import.
How raw input becomes structured, searchable knowledge.
Memory
Wiki
Every memory (from agents or integrations) goes through the same pipeline.
1
Episode creation
The raw input is saved as an episode, a snapshot of a conversation or data event. Episodes are the building blocks of memory.
2
Entity extraction
Membase identifies key entities from the episode: people, projects, tools, preferences, decisions, dates, and other meaningful concepts.
Example entities from a conversation
"Let's use Zustand instead of Redux"→ Entities: Zustand, Redux, state management decision
3
Graph construction
Extracted entities are added to your knowledge graph. New entities connect to existing ones when they overlap, so “Zustand” mentioned in two different conversations becomes one entity with two linked episodes.
4
Deduplication and merging
If the same fact appears in multiple episodes, Membase merges them. When new information contradicts an existing memory, the latest data takes priority.
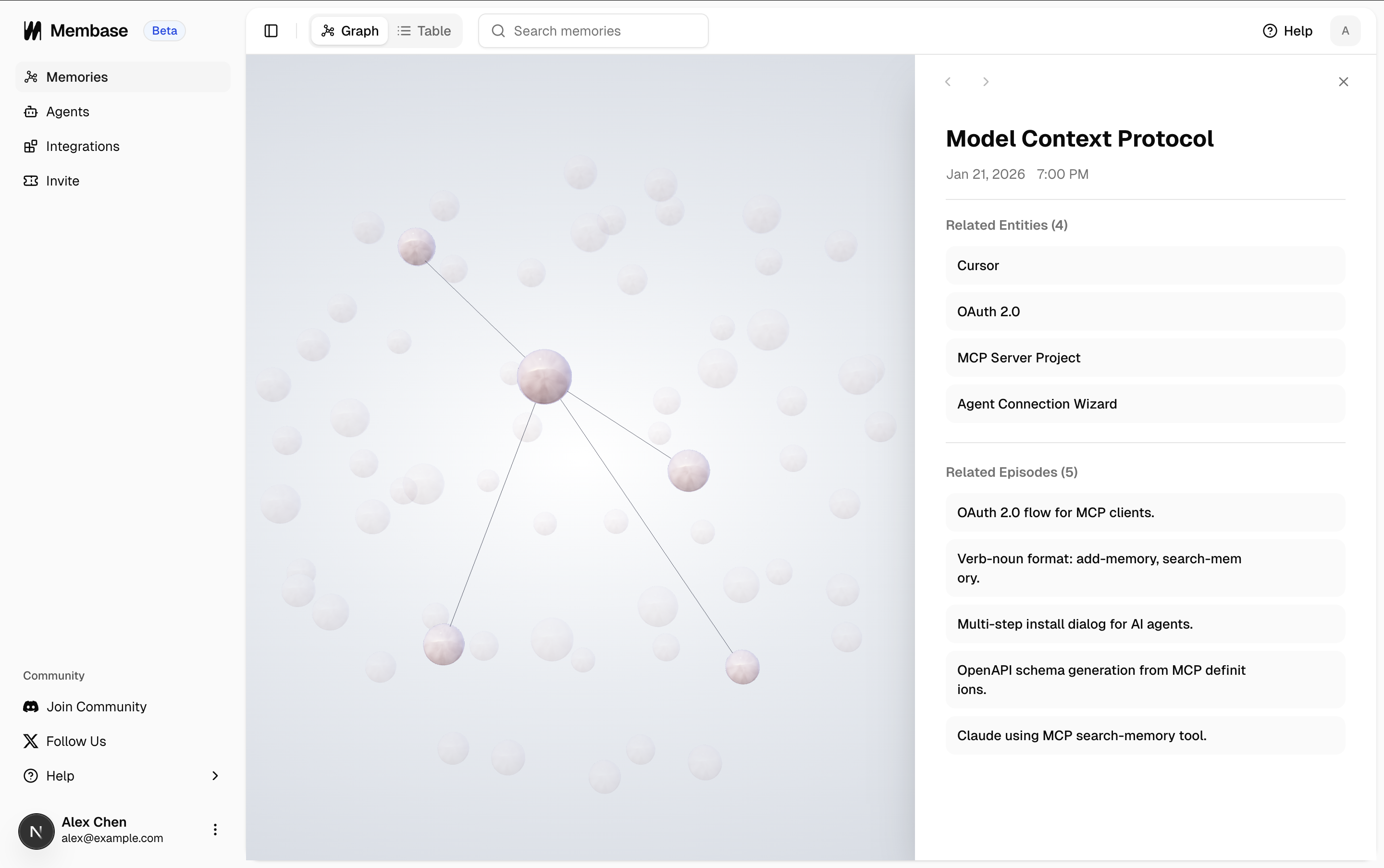
The result is a continuously growing knowledge graph where entities, relationships, and episodes are all interconnected.
Knowledge graph view in the Membase dashboard
Wiki documents are stored as markdown plus structural metadata for fast retrieval.
1
Document storage
The document’s title and markdown content are saved to the Wiki store, filed into a Project or Basic.
2
Wikilink parsing
Membase parses [[wikilinks]] in the content and maintains a bidirectional link graph. This is what powers backlinks, the force-directed graph view, and instant [[ autocomplete in the editor.
3
Search indexing
Each document is indexed for hybrid search: a full-text index (BM25-style) for keyword queries and a semantic embedding for meaning-based queries. Both are fused with Reciprocal Rank Fusion (RRF) at query time.
4
Source provenance and review
Imported and synced documents keep source provenance when available. When a source update or generated change needs review, Membase can route it through Inbox Review so you can inspect, edit, accept, reject, or undo the change.
How context flows back when an agent or Chat needs it.
Memory
Wiki
1
Agent calls search_memory
The agent sends a query describing what personal context it needs. This happens automatically when prior context would improve the response.
Example
You: "Set up a new component for the settings page."→ Agent calls search_memory: "project tech stack, component preferences"
2
Membase searches the knowledge graph
The query is matched against your graph using semantic search. Relevant episodes and their connected entities are retrieved.Relevant results might include:
“Uses Next.js with TypeScript”
“Prefers functional components”
“State management: Zustand”
“Styling: Tailwind CSS”
3
Ranked results returned
Results are scored by relevance and returned as episode-centric bundles. Only the most useful context is included, keeping the agent’s context window clean.
4
Agent responds with full context
The agent generates a response grounded in your actual preferences and project details, without you having to repeat any of it.
Here’s a real example: Claude retrieving a git workflow from Membase during a conversation.
Claude retrieving stored git workflow context from Membase
1
Agent calls search_wiki
The agent sends a query describing what factual knowledge it needs.
Example
You: "Remind me how our auth middleware handles expired tokens."→ Agent calls search_wiki: "auth middleware expired token"
2
Membase runs hybrid search
The query is matched with both full-text keyword search and semantic similarity. The two rankings are fused with Reciprocal Rank Fusion, so you get solid results whether the query is literal or conceptual.
3
Full document bodies returned
Unlike memory episodes, wiki results include the full document body, so the agent has enough context to answer directly instead of juggling fragments.
4
Agent responds with full context
The agent grounds its answer in the retrieved documents and cites them if your prompt encourages citations.
Chat in Dashboard can use both search_memory and search_wiki when stored context could help, then combine the results into a single answer with citations. Your agents should do the same when the user’s question could benefit from either store.
This entire cycle (ingest → structure → retrieve) runs continuously as you use Membase. The more you interact, the richer both stores become, and the smarter your agents get.